
The power of installed-base snap metrics
by cprov on 27 November 2018
The Snap Store is able to provide insightful information to Independent Software Vendors (ISVs) about usage of their snap applications. Our goal is to help snap publishers interact better with their users and make the most of their relationship.
The primary metric provided by the store is the active installed-base. We will show how this data empowers publishers by tracking the flow of new releases, analysing the breakdown of users across risks and major versions, and seeing the distribution across operating systems.
Where can I find metrics for my snaps? 🔍
Snap metrics are available for publishers logged-in at https://snapcraft.io. Simply access https://snapcraft.io/$YOUR_SNAP_NAME/metrics
Or navigate from the list of My published snaps to a particular snap:
Then access the Metrics context:
Weekly active devices
The store plots metrics from a weekly interval (rolling last 7 days), which nicely accommodates the variety of usage profiles we have observed, from always-connected IoT devices and cloud instances to weekend-experiment installations. Essentially, the store will look back 7 days and count each unique device-serial refresh request containing the given snap that reported in at least once in that period.
The default plotting interval is Past 30 days, but publishers can select different predefined intervals according to their interest.
Singing development songs 🎶
The default breakdown of the active devices count is by version, because it speaks intimately to people involved with the software project. Each specific version may refer to a set of features, an API or ABI change or a particular bug fix and, more importantly, it’s the same version referred to in other distribution systems. Specific version semantics can be fully expressed for each snap revision in snapcraft.yaml, either manually or programmatically.
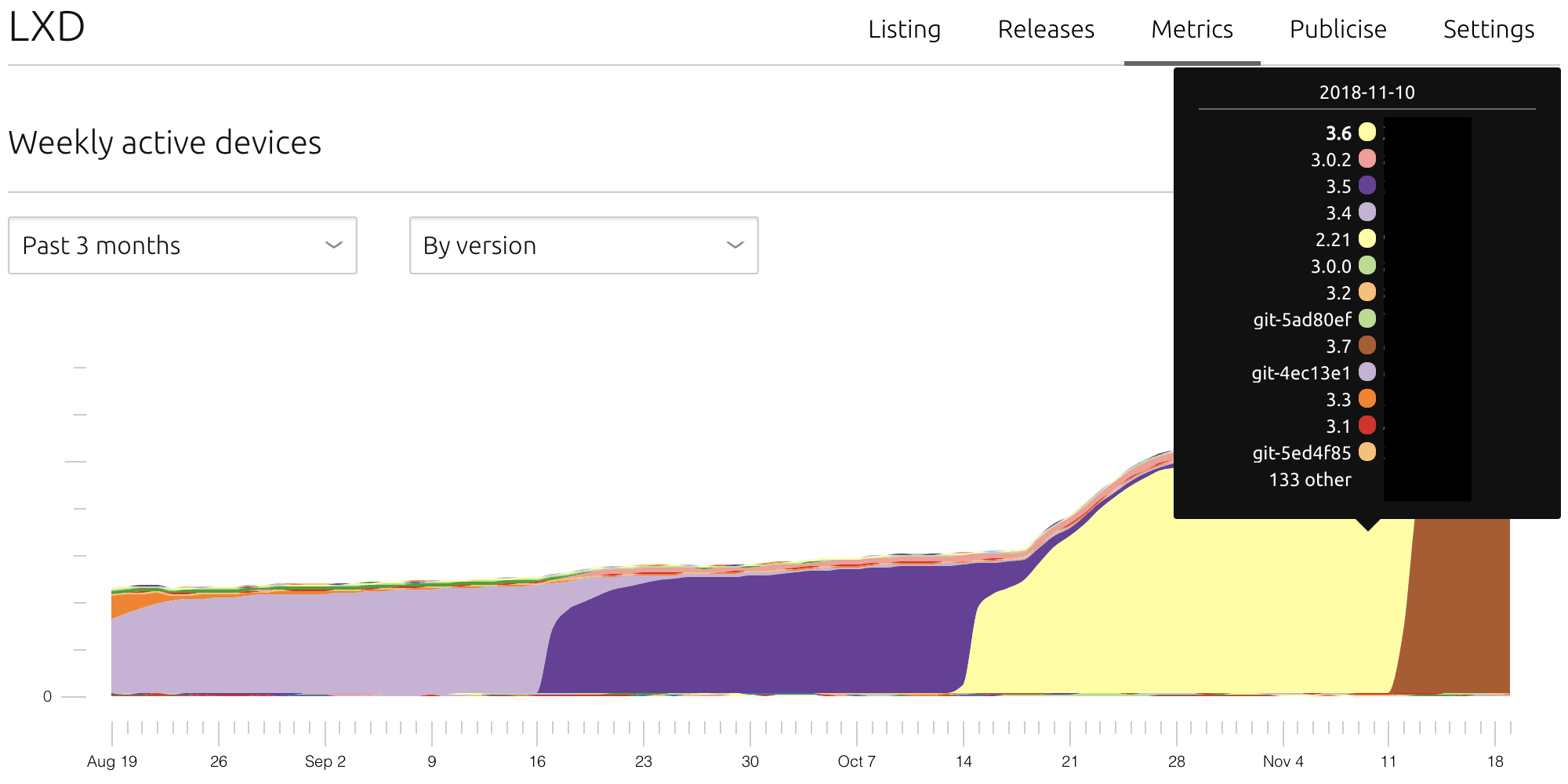
Publishers can visualise how many users are automatically updated and using the just-released bugfix or new feature. Or the opposite, because snaps are transactional and automatically rollback to the previous working version in case of a refresh failure, publishers can recognize a failing revision that will not “stick” to the current installed base.
During the next development cycle, we will work on snap health-checks in order to be more informative in case of failures. While users are unaffected due to the automatic rollback, publishers will benefit of the information collected on actual installation or refresh failures for providing an effective fix.
Respecting choices ✎
Snaps introduce a novel form of allowing publishers and users of their application to establish and agree on certain behaviours when distributing and installing software.
Channels are, in essence, a social protocol by which users express their expectations about how much risk they are willing to take.
For instance:
$ snap install dependable-app --channel=3.0/stable
Expresses the user’s investment on the continuity of the `3.0` major series (the snap track), being it the application file format, a set of major features or GUI appearance and also their request for the highest possible stability on updates.
On the other hand, it’s also possible for users to express completely different expectations for a non-critical applications:
$ snap install awesome-app --channel=edge
By omitting the track, users automatically fall on the development application branch (snap `latest` track) and `edge` is the highest level of risk available. For the sake of illustration, `edge` is typically where revisions from the project’s Continuous Integration (CI) process are released, the “tip” of the repository where pretty much everything can happen, no guarantees.
Selecting the By Channel breakdown, publishers to visualize trends on their users’ channel choices:
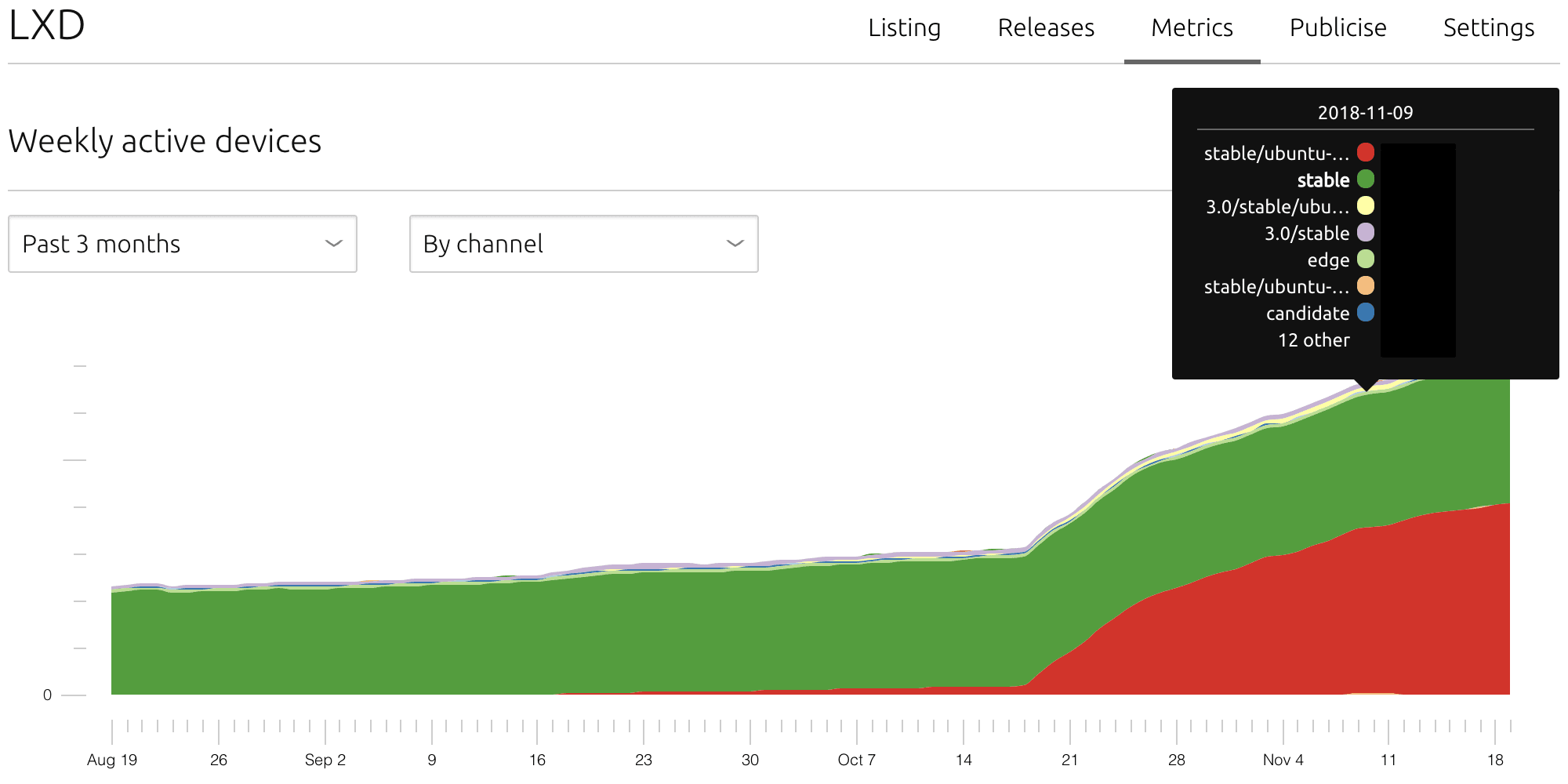
More information about snap channels can be found in the official documentation. The important point here is that once publishers can visualise trends on channels, they can start socialising the project-specific expectations of those choices and understand the distribution of their user base across them.
Users who can afford to track non-stable channels will ensure revisions coming from CI have enough real-world coverage and help the entire community to spot and fix bugs before they are exposed to a wider audience. After all, with snaps, it’s not a permanent decision and users can easily switch to `stable` or another risk at any time:
$ snap refresh awesome-app --channel=stable ... $ snap refresh awesome-app --channel=candidate ...
In terms of continuity, it is helpful to see how many users are invested in a particular series of the application and work out mechanisms to ease their migration to where the development focus is, which will most certainly maximize efforts. Snaps will soon support parallel installs, which will allow complex migrations to be performed safely within the same system:
$ snap install dependable-app --channel=stable dependable-app_latest ... $ dependable-app_latest.migrate_from_3.0 <my-data-from-3.0> ...
Keeping promises 🤞
The next breakdown is By OS (Operating Systems) which allows publishers to visualize the trends of their applications across multiple operating systems and their versions, leveraging one of the most valuable promises of the snap ecosystem: providing the most compelling application delivery system across all Linux distributions.
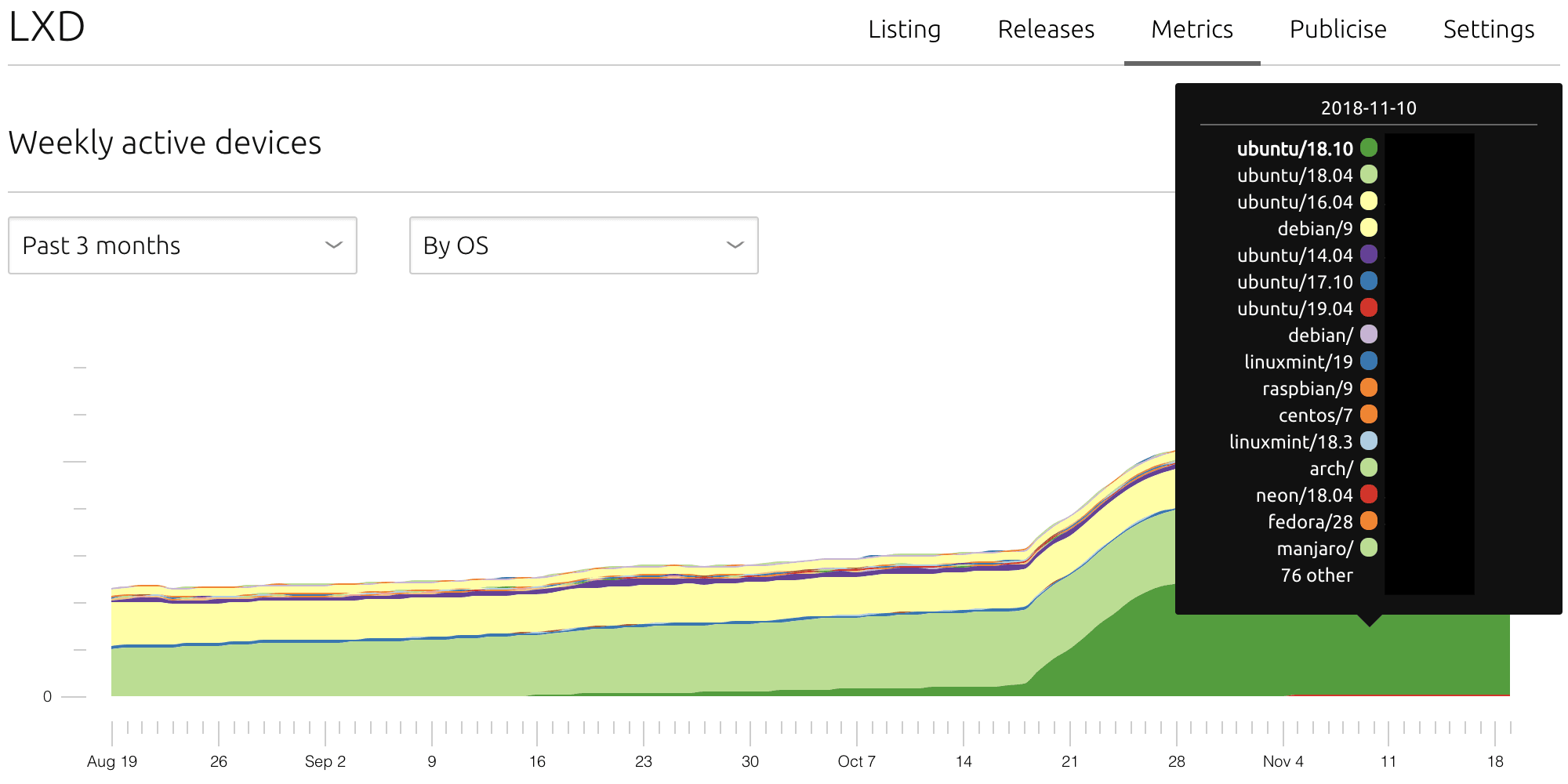
Publishers can evaluate the costs and impacts of specific development efforts for supporting distro-specific features and campaigns targeted to specific distribution or product audiences.
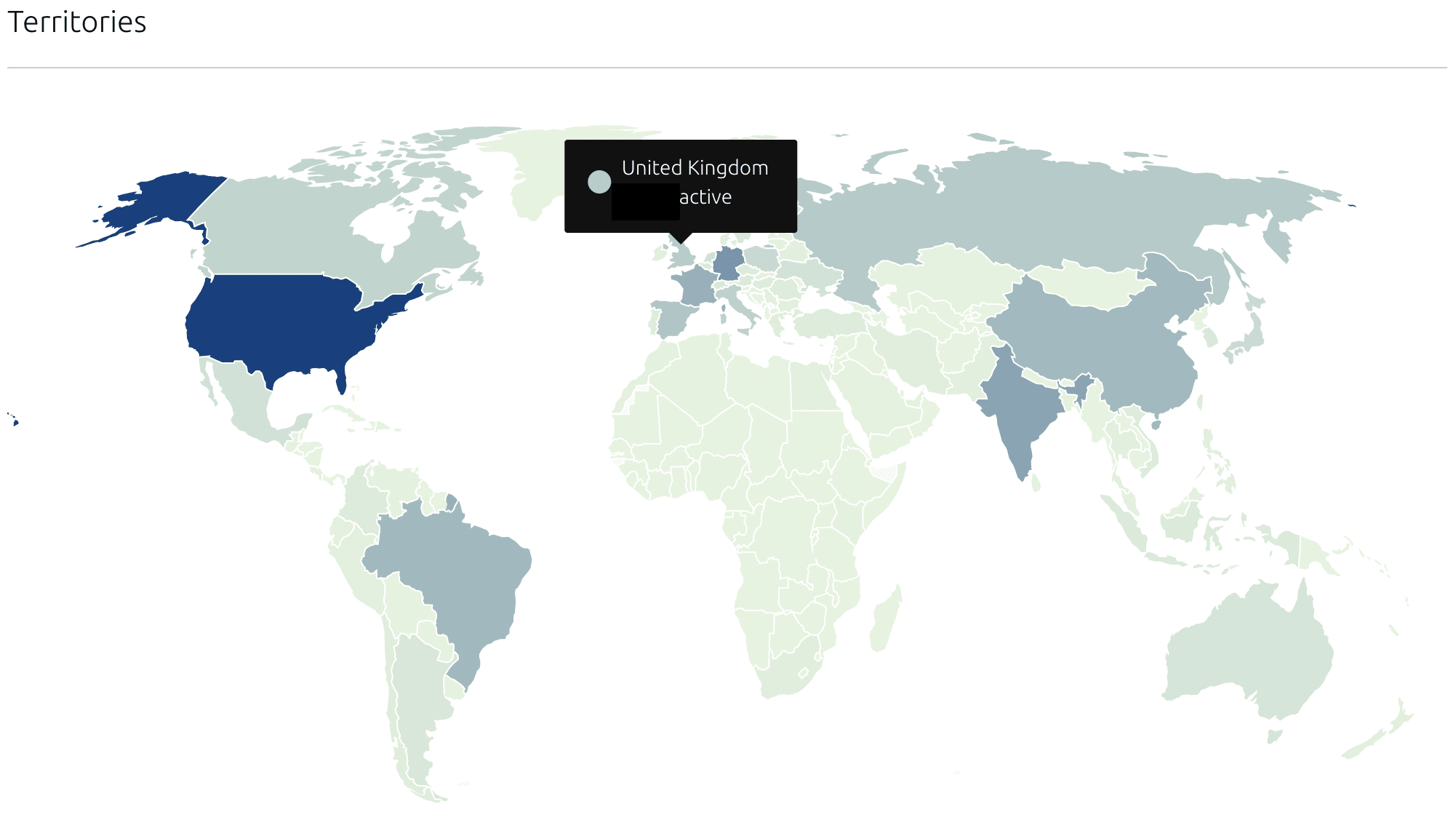
Everybody needs a map 🗺
Finally, the Snap Store geographically locates refresh attempts at the country-level. This allows publishers to visualise aspects of their application related to demography, like internationalisation and geographic adoption.
How exactly does it work under the hood ? 🤔
The Snap Store assigns an anonymous identifier, the device-serial, to every new snapd client it sees. This exchange usually happens when a new installation tries to contact the store during the first-boot and it is persisted for the entire machine lifespan.
IoT devices and other specific workflows based on Ubuntu Core, use a more elaborate device-serial assignment which can be integrated with hardware identification capabilities and their factory provisioning process. This is not the case for classic systems (Ubuntu, Debian, Fedora, OpenSuse, etc): they simply get assigned a random identifier that gets saved on disk.
Systems running snapd will periodically (can be adjusted locally according to the needs) make a refresh request to the store, checking the for the most recent release of each installed snap. At that moment, they inform the store of their device-serial along with a list of the currently installed snaps. The store simply infers the list of active applications from the clients’ requests in a given period.
There is a lot more to talk about…
We are keen to hear ideas from you in the Snap Forum ! We are constantly improving the user experience in the web UI and displaying insightful information to snap publishers.
All metrics that are present in the web UI and few additional ones are available in the Store Metrics APIs. ISVs can easily integrate the snap store data into their internal dashboards and benefit from them in their decision process.
Also, thanks to the LXD team for allowing use of their metrics.